CONTENTS
- NAME
- VERSION
- DESCRIPTION
- SYNOPSIS
- CORE MODULES
- MCE EXTRAS
- MCE MODELS
- MISCELLANEOUS
- REQUIREMENTS
- SOURCE AND FURTHER READING
- SEE ALSO
- AUTHOR
- COPYRIGHT AND LICENSE
#NAME
MCE - Many-Core Engine for Perl providing parallel processing capabilities
#VERSION
This document describes MCE version 1.902
Many-Core Engine (MCE) for Perl helps enable a new level of performance by maximizing all available cores.
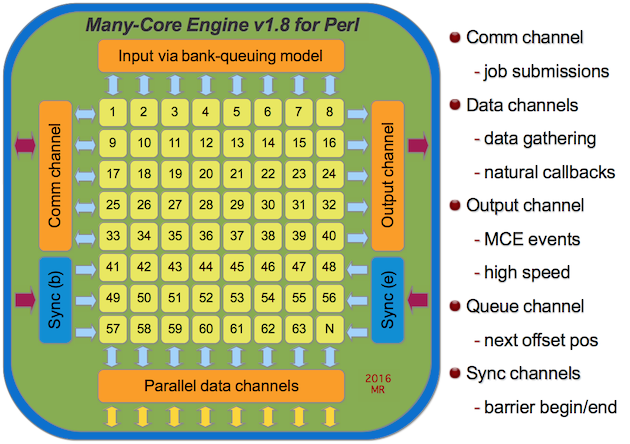
#DESCRIPTION
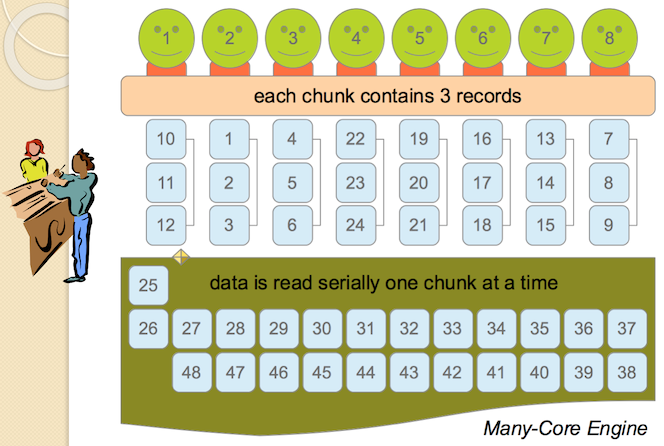
MCE spawns a pool of workers and therefore does not fork a new process per each element of data. Instead, MCE follows a bank queuing model. Imagine the line being the data and bank-tellers the parallel workers. MCE enhances that model by adding the ability to chunk the next n elements from the input stream to the next available worker.
#SYNOPSIS
This is a simplistic use case of MCE running with 5 workers.
# Construction using the Core API
use MCE;
my $mce = MCE->new(
max_workers => 5,
user_func => sub {
my ($mce) = @_;
$mce->say("Hello from " . $mce->wid);
}
);
$mce->run;
# Construction using a MCE model
use MCE::Flow max_workers => 5;
mce_flow sub {
my ($mce) = @_;
MCE->say("Hello from " . MCE->wid);
};The following is a demonstration for parsing a huge log file in parallel.
use MCE::Loop;
MCE::Loop->init( max_workers => 8, use_slurpio => 1 );
my $pattern = 'something';
my $hugefile = 'very_huge.file';
my @result = mce_loop_f {
my ($mce, $slurp_ref, $chunk_id) = @_;
# Quickly determine if a match is found.
# Process the slurped chunk only if true.
if ($$slurp_ref =~ /$pattern/m) {
my @matches;
# The following is fast on Unix, but performance degrades
# drastically on Windows beyond 4 workers.
open my $MEM_FH, '<', $slurp_ref;
binmode $MEM_FH, ':raw';
while (<$MEM_FH>) { push @matches, $_ if (/$pattern/); }
close $MEM_FH;
# Therefore, use the following construction on Windows.
while ( $$slurp_ref =~ /([^\n]+\n)/mg ) {
my $line = $1; # save $1 to not lose the value
push @matches, $line if ($line =~ /$pattern/);
}
# Gather matched lines.
MCE->gather(@matches);
}
} $hugefile;
print join('', @result);The next demonstration loops through a sequence of numbers with MCE::Flow.
use MCE::Flow;
my $N = shift || 4_000_000;
sub compute_pi {
my ( $beg_seq, $end_seq ) = @_;
my ( $pi, $t ) = ( 0.0 );
foreach my $i ( $beg_seq .. $end_seq ) {
$t = ( $i + 0.5 ) / $N;
$pi += 4.0 / ( 1.0 + $t * $t );
}
MCE->gather( $pi );
}
# Compute bounds only, workers receive [ begin, end ] values
MCE::Flow->init(
chunk_size => 200_000,
max_workers => 8,
bounds_only => 1
);
my @ret = mce_flow_s sub {
compute_pi( $_->[0], $_->[1] );
}, 0, $N - 1;
my $pi = 0.0; $pi += $_ for @ret;
printf "pi = %0.13f\n", $pi / $N; # 3.1415926535898#CORE MODULES
Four modules make up the core engine for MCE.
- #MCE::Core
-
This is the POD documentation describing the core Many-Core Engine (MCE) API. Go here for help with the various MCE options. See also, MCE::Examples for additional demonstrations.
- #MCE::Mutex
-
Provides a simple semaphore implementation supporting threads and processes. Two implementations are provided; one via pipes or socket depending on the platform and the other using Fcntl.
- #MCE::Signal
-
Provides signal handling, temporary directory creation, and cleanup for MCE.
- #MCE::Util
-
Provides utility functions for MCE.
#MCE EXTRAS
There are 5 add-on modules for use with MCE.
- #MCE::Candy
-
Provides a collection of sugar methods and output iterators for preserving output order.
- #MCE::Channel
-
Introduced in MCE 1.839, provides queue-like and two-way communication capability. Three implementations
Simple,Mutex, andThreadsare provided.Simpledoes not involve locking whereasMutexandThreadsdo locking transparently usingMCE::Mutexandthreadsrespectively. - #MCE::Child
-
Also introduced in MCE 1.839, provides a threads-like parallelization module that is compatible with Perl 5.8. It is a fork of MCE::Hobo. The difference is using a common
MCE::Channelobject when yielding and joining. - #MCE::Queue
-
Provides a hybrid queuing implementation for MCE supporting normal queues and priority queues from a single module. MCE::Queue exchanges data via the core engine to enable queuing to work for both children (spawned from fork) and threads.
- #MCE::Relay
-
Provides workers the ability to receive and pass information orderly with zero involvement by the manager process. This module is loaded automatically by MCE when specifying the
init_relayMCE option.
#MCE MODELS
The MCE models are sugar syntax on top of the MCE::Core API. Two MCE options (chunk_size and max_workers) are configured automatically. Moreover, spawning workers and later shutdown occur transparently behind the scene.
Choosing a MCE Model largely depends on the application. It all boils down to how much automation you need MCE to handle transparently. Or if you prefer, constructing the MCE object and running using the core MCE API is fine too.
- #MCE::Grep
-
Provides a parallel grep implementation similar to the native grep function.
- #MCE::Map
-
Provides a parallel map implementation similar to the native map function.
- #MCE::Loop
-
Provides a parallel for loop implementation.
- #MCE::Flow
-
Like
MCE::Loop, but with support for multiple pools of workers. The pool of workers are configured transparently via the MCEuser_tasksoption. - #MCE::Step
-
Like
MCE::Flow, but adds aMCE::Queueobject between each pool of workers. This model, introduced in 1.506, allows one to pass data forward (left to right) from one sub-task into another with little effort. - #MCE::Stream
-
This provides an efficient parallel implementation for chaining multiple maps and greps transparently. Like
MCE::FlowandMCE::Step, it too supports multiple pools of workers. The distinction is thatMCE::Streampasses data from right to left and done for you transparently.
#MISCELLANEOUS
Miscellaneous additions included with the distribution.
- #MCE::Examples
-
Describes various demonstrations for MCE including a Monte Carlo simulation.
- #MCE::Subs
-
Exports functions mapped directly to MCE methods; e.g. mce_wid. The module allows 3 options; :manager, :worker, and :getter.
#REQUIREMENTS
Perl 5.8.0 or later.
#SOURCE AND FURTHER READING
The source and examples are hosted at GitHub.
#SEE ALSO
Refer to the MCE::Core documentation where the API is described.
MCE::Shared provides data sharing capabilities for MCE. It includes MCE::Hobo for running code asynchronously with the IPC handled by the shared-manager process.
#AUTHOR
Mario E. Roy, <marioeroy AT gmail DOT com>
#COPYRIGHT AND LICENSE
Copyright (C) 2012-2024 by Mario E. Roy
MCE is released under the same license as Perl.
See https://dev.perl.org/licenses/ for more information.